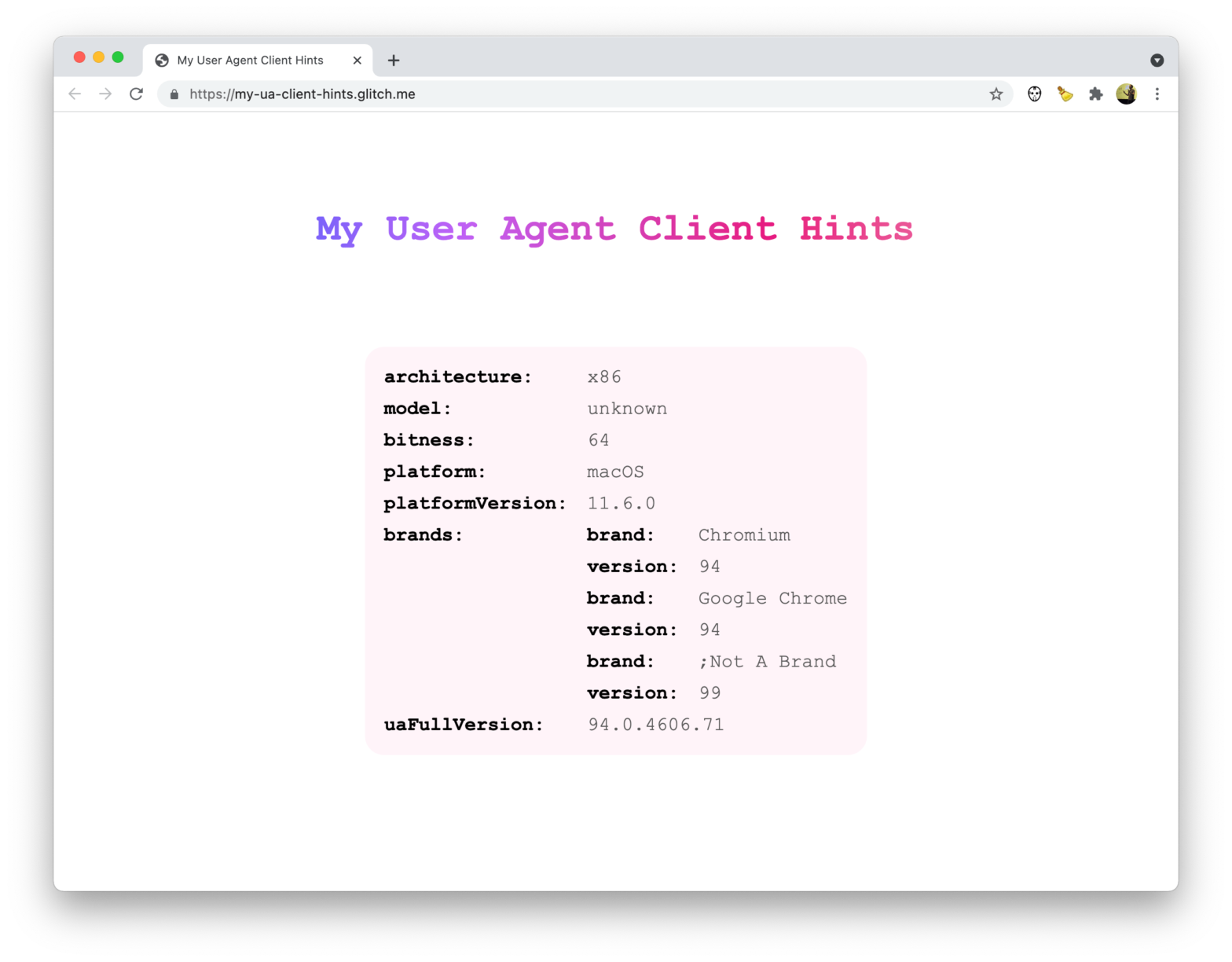
Patrick Brosset created a handy website that dumps the UA Client Hints your browser sends. Might come in handy. My User Agent Client Hints → Over at web.dev you can find an article that introduces User-Agent Client Hints
A rather geeky/technical weblog, est. 2001, by Bramus
Patrick Brosset created a handy website that dumps the UA Client Hints your browser sends. Might come in handy. My User Agent Client Hints → Over at web.dev you can find an article that introduces User-Agent Client Hints
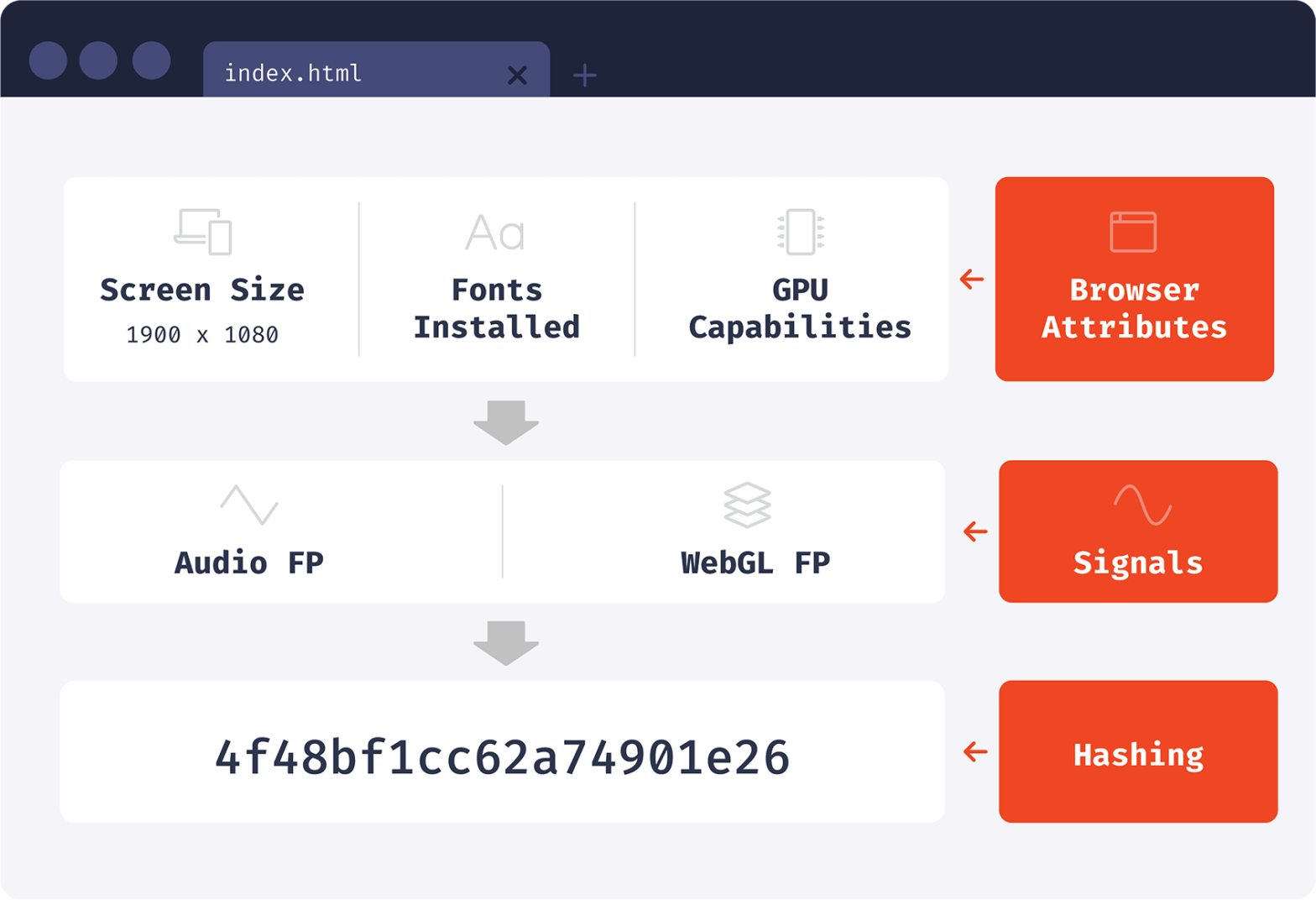
When generating a browser identifier, we can read browser attributes directly or use attribute processing techniques first. One of the creative techniques that we’ll discuss today is audio fingerprinting. Using an Oscillator and a Compressor they can basically calculate a specific number that identifies you. Every browser we have on our testing laptops generate a …
Continue reading “How the Web Audio API is used for browser fingerprinting”

State Partitioning is an interesting privacy feature shipping with Firefox 86. With State Partitioning, shared state such as cookies, localStorage, etc. will be partitioned (isolated) by the top-level website you’re visiting. In other words, every first party and its embedded third-party contexts will be put into a self-contained bucket. Applies to every embedded third-party resource …

A video-version of How tracking pixels work by Vox: In this video, we explain how cookies work and what you should know about how they’re being used. And we get a little help from the man who invented them. Spot on “Finding Dory” analogy. One thing where they do go off a bit is that …
👋 This post also got published on Medium. If you like it, please give it some love a clap over there. Late 2016, Stoyan Stefanov published “Oversharing with the browser’s autofill”. It’s an article on stealing personal data using the browsers their form autofill feature. The attack works by leveraging abusing the fact that autocompletion …
A few years ago window.getComputedStyle and the like where adjusted to return the default color of links, instead of the actual color on screen. Security and privacy were the driving factors behind that decision: by styling :visited links with a different color than their non-visited counterparts, a hacker could easily determine which sites a user …
Continue reading “Stealing your browser history with the W3C Ambient Light Sensor API”
favicon.ico and redirect links as a privacy leakWithout your consent most major web platforms leak whether you are logged in. This allows any website to detect on which platforms you’re signed up. Since there are lots of platforms with specific demographics an attacker could reason about your personality, too. The attack works by loading in a website’s redirect script, with its favicon …
Continue reading “favicon.ico and redirect links as a privacy leak”
“lastActiveTimes”: { “3443534”: 1456065265, “675631492”: 1456066386, “8657643”: 1456062331, “255277634”: 1456052450, “6423324”: 1456065173, “235323452”: 1456065096, “3265233223”: 1456066381, “2432885644”: 1456064016, “7464340313”: 1456062500 } In the HTML source code of Messenger.com you can find an object containing userids associated with timestamps of last activity – as shown above. Given this it’s really easy to scrape and combine this …
Continue reading “How you can use Facebook to track your friends’ sleeping habits”
Interesting project by Russian photographer Egor Tsvetkov in which he took photos of random, anonymous, people riding the subway, and then running them through a face recognition app named FindFace. The result: 70% of those photographed could be linked to one or social network profiles of ‘m, thus un-anonymizing them. End of anonymity: Identification of …