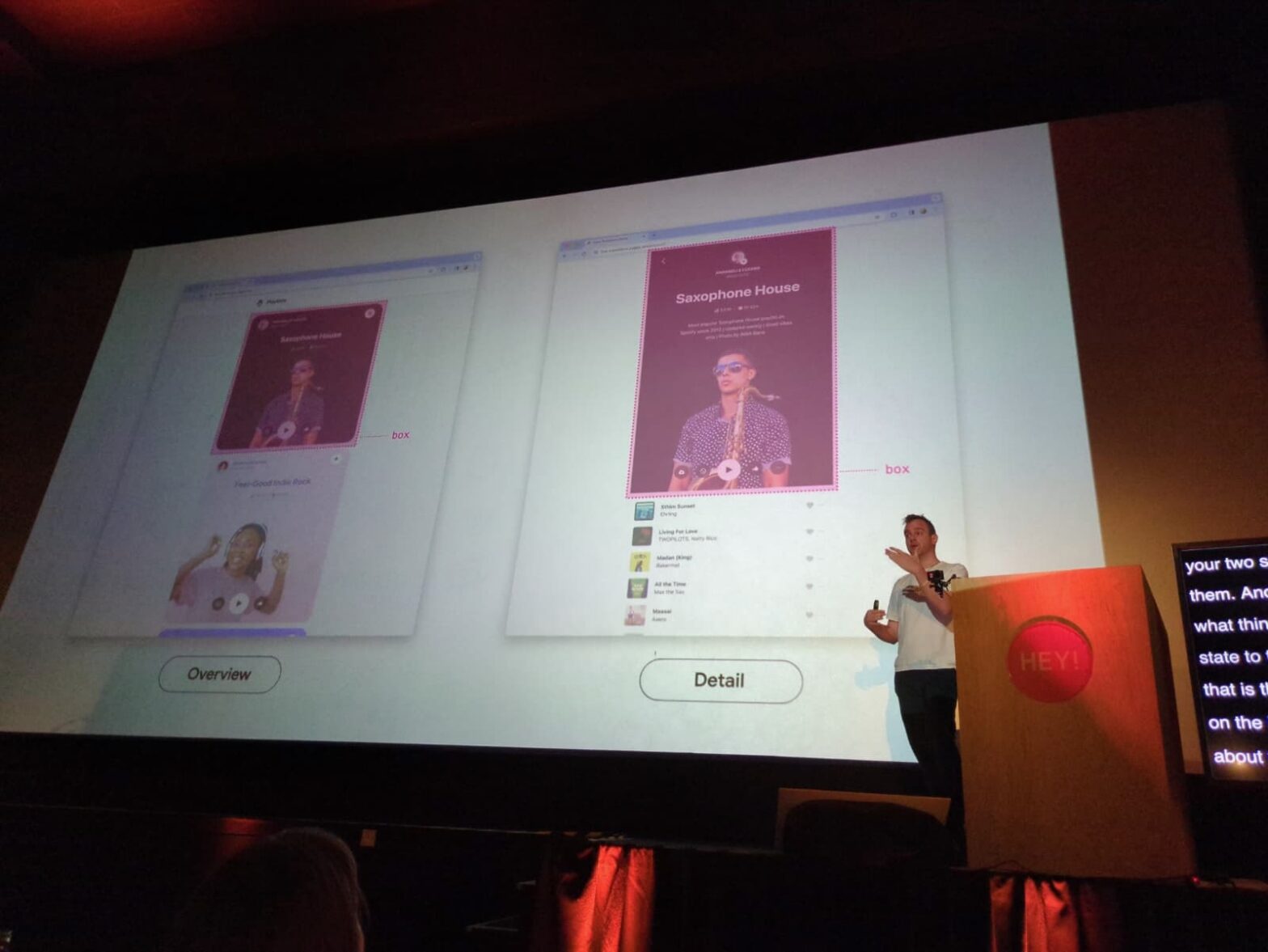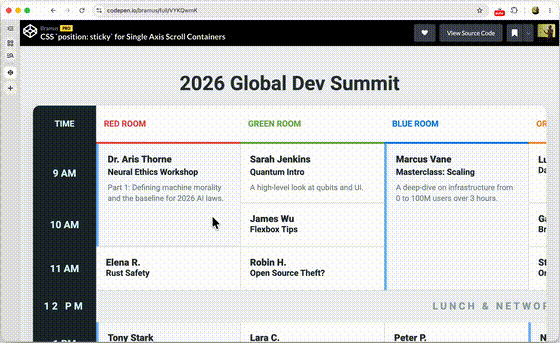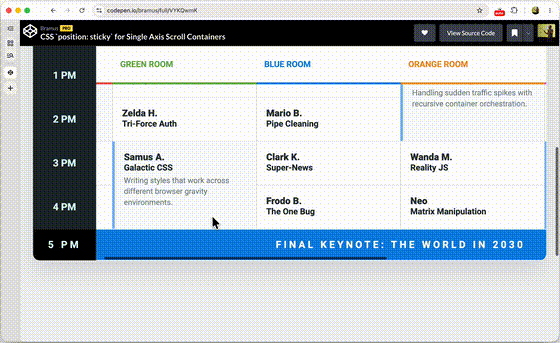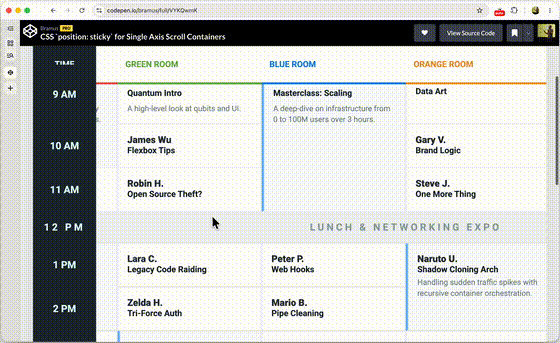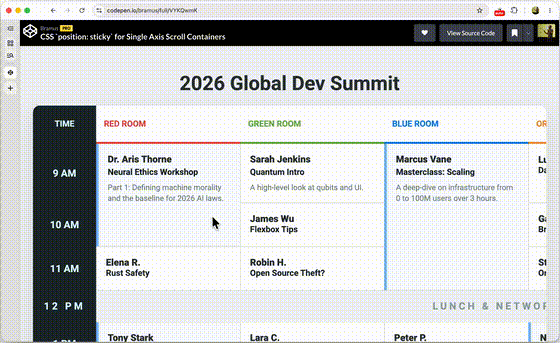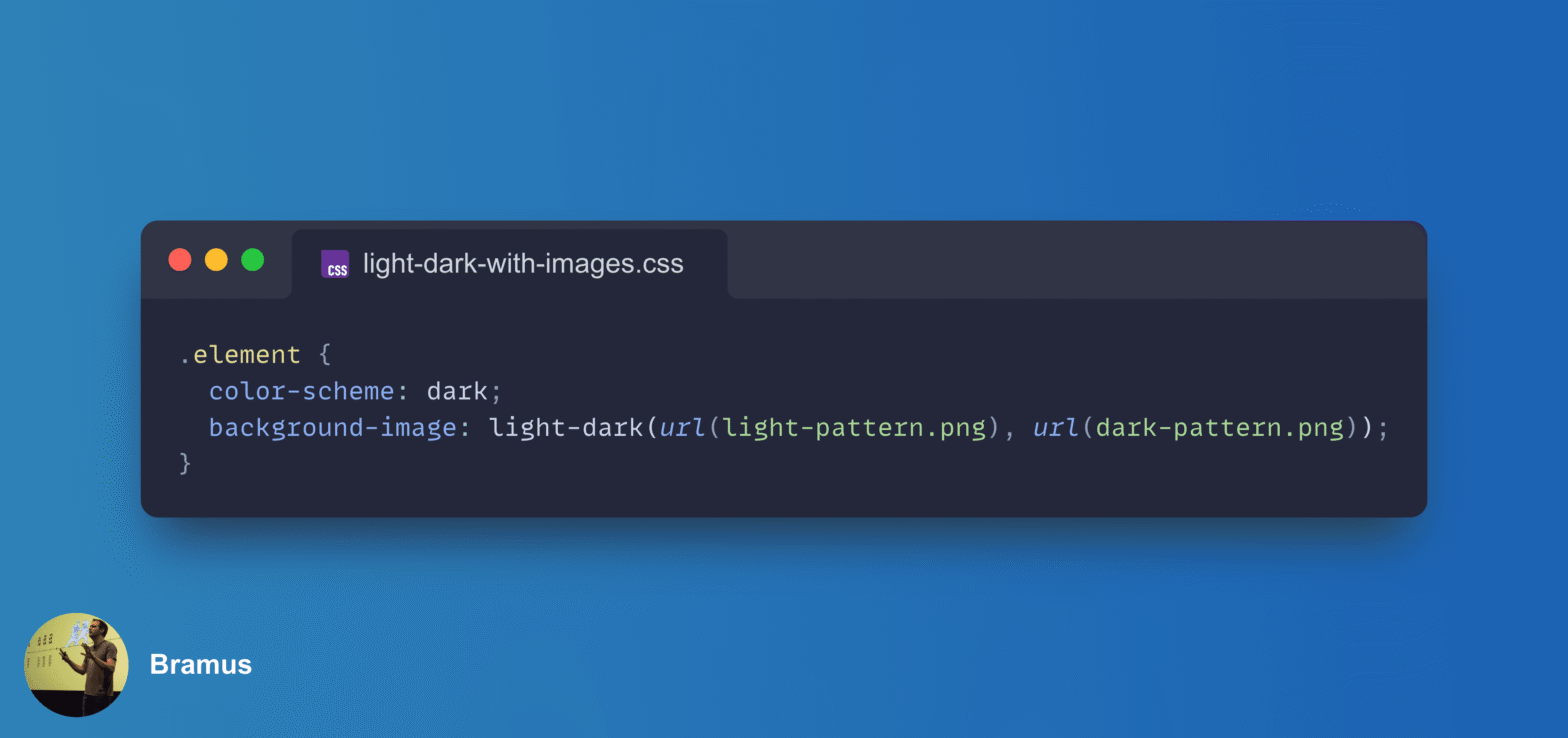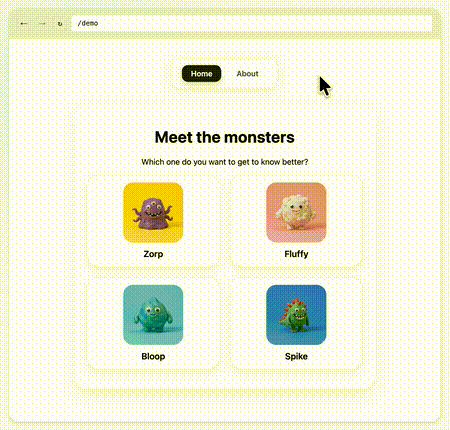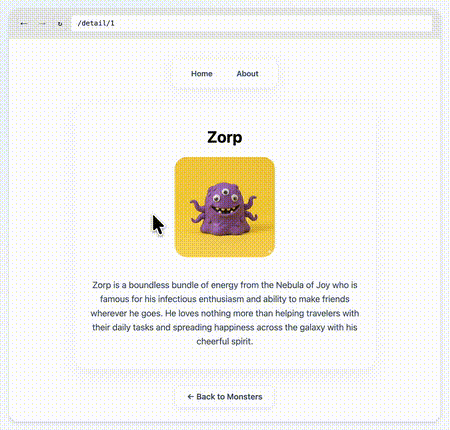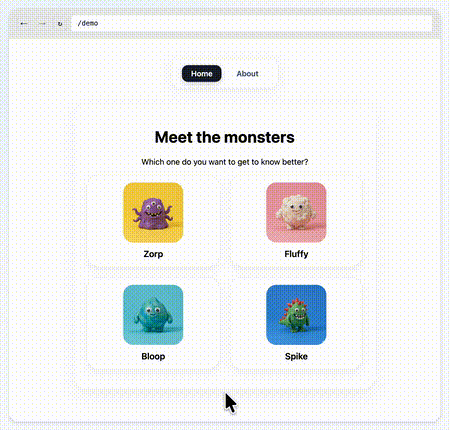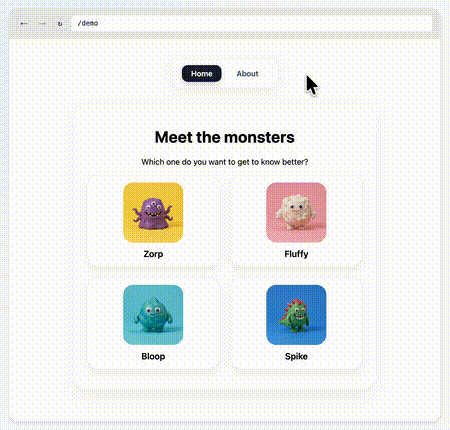
One of the things that we at Chrome have been thinking about for a while now is a way to do declarative route and navigation matching in CSS. Together with Noam Rosenthal and David Baron I’ve been working on it for the past few months.
After an initial introduction at the CSS Working Group back in January, and a quick feedback session at CSS Day in June, we think we have something that is ready for further discussion.
At next week’s CSS Working Group F2F (face-to-face) meeting in Berlin, we’ll be presenting our current line of thinking. This post is a quick intro to the concepts we’ll be covering.