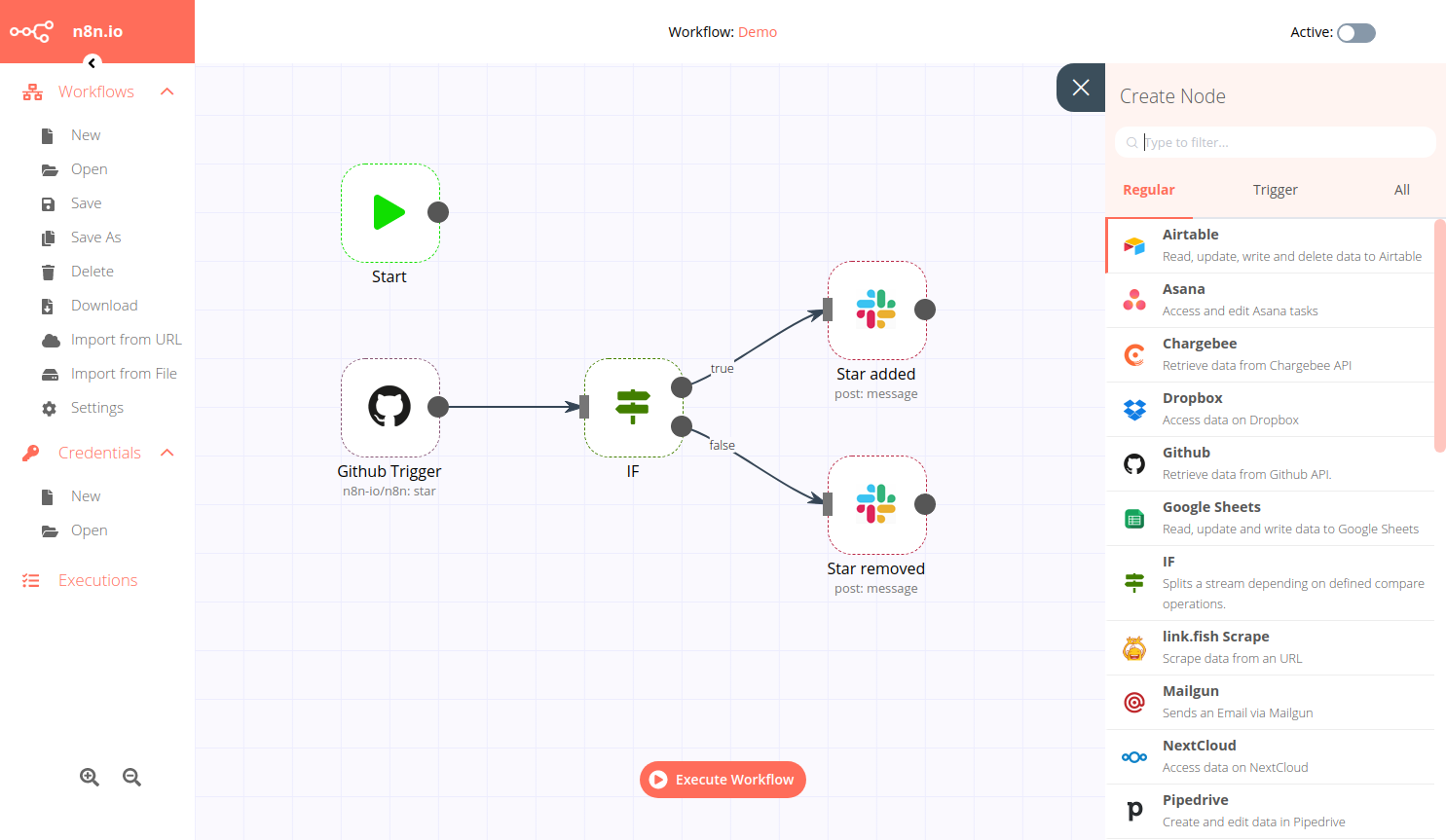
With n8n everyone can have their own free node-based workflow automation tool. n8n is self-hostable, so the data stays with you. It can be easily extended and so also used with in-house tools and allows to automate complex tasks. Launch it directly from the CLI via npx n8n or run the offered Docker container. If …