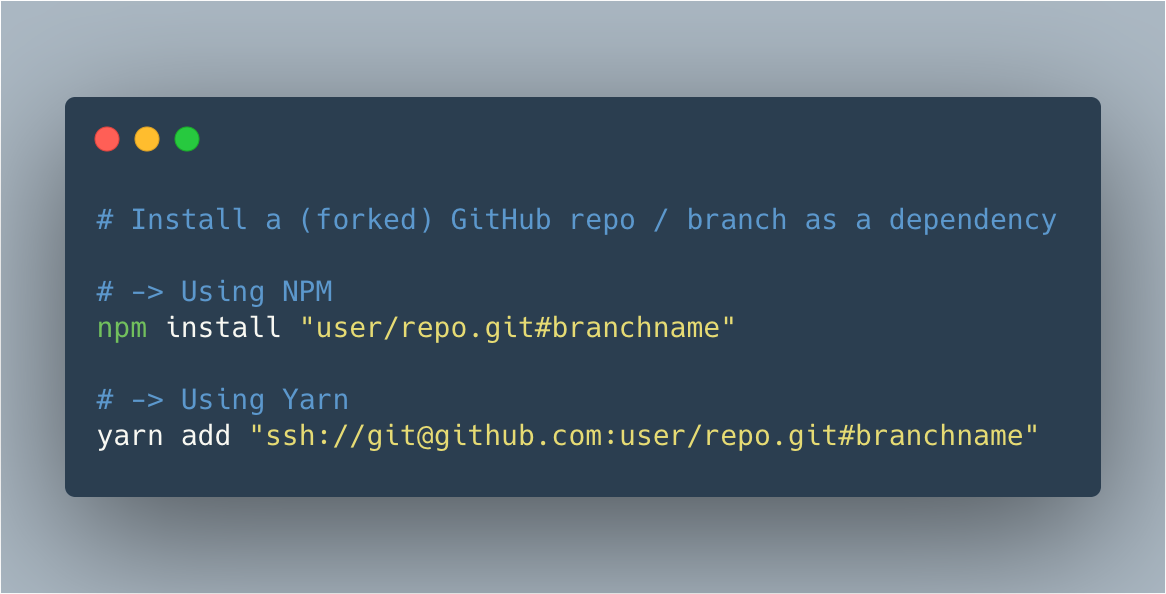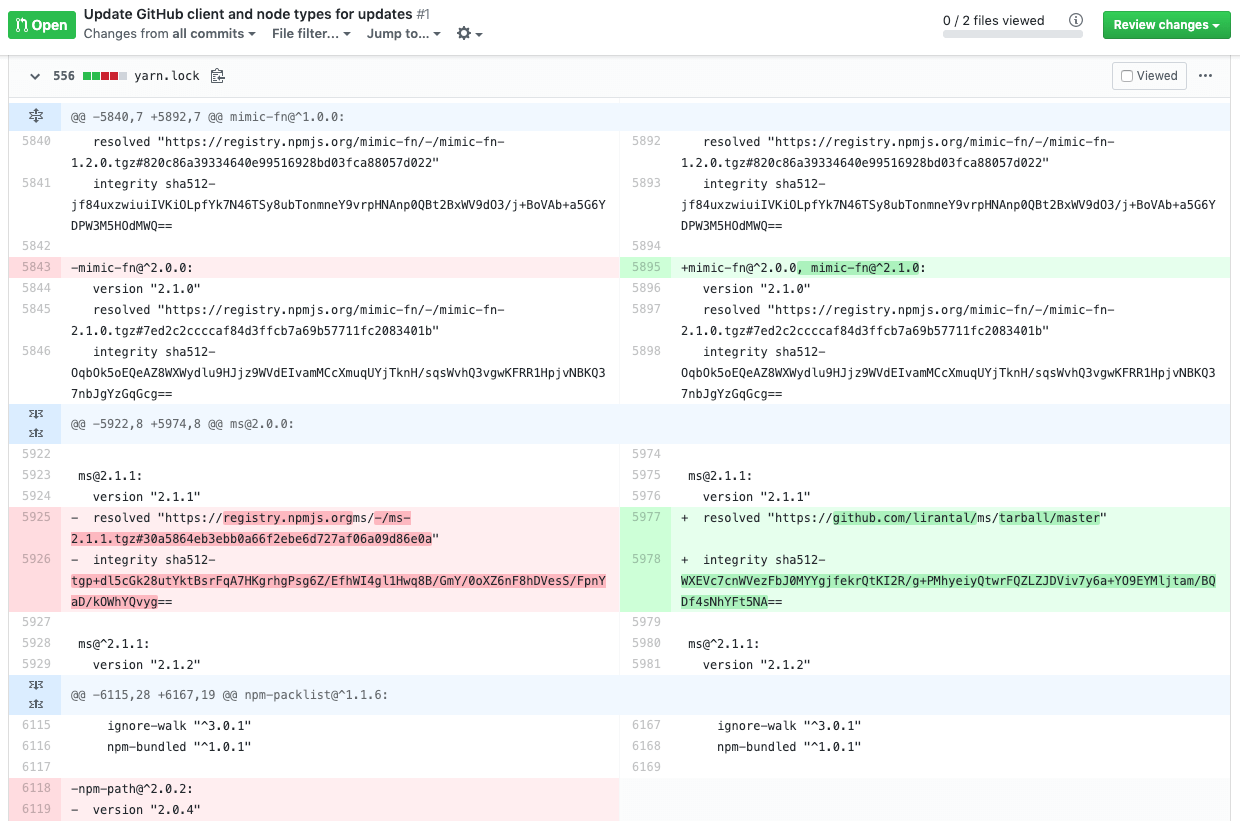
When watching a diff that contains a lockfile (say: a yarn.lock for example) on GitHub, GitHub doesn’t always show the differences (see screenshot above) as the changes in such files tend to be quite big. And even if it were to show the changes, does one really take a close look into it? With this …
Continue reading “Beware when merging Pull Requests with a changed lockfile”