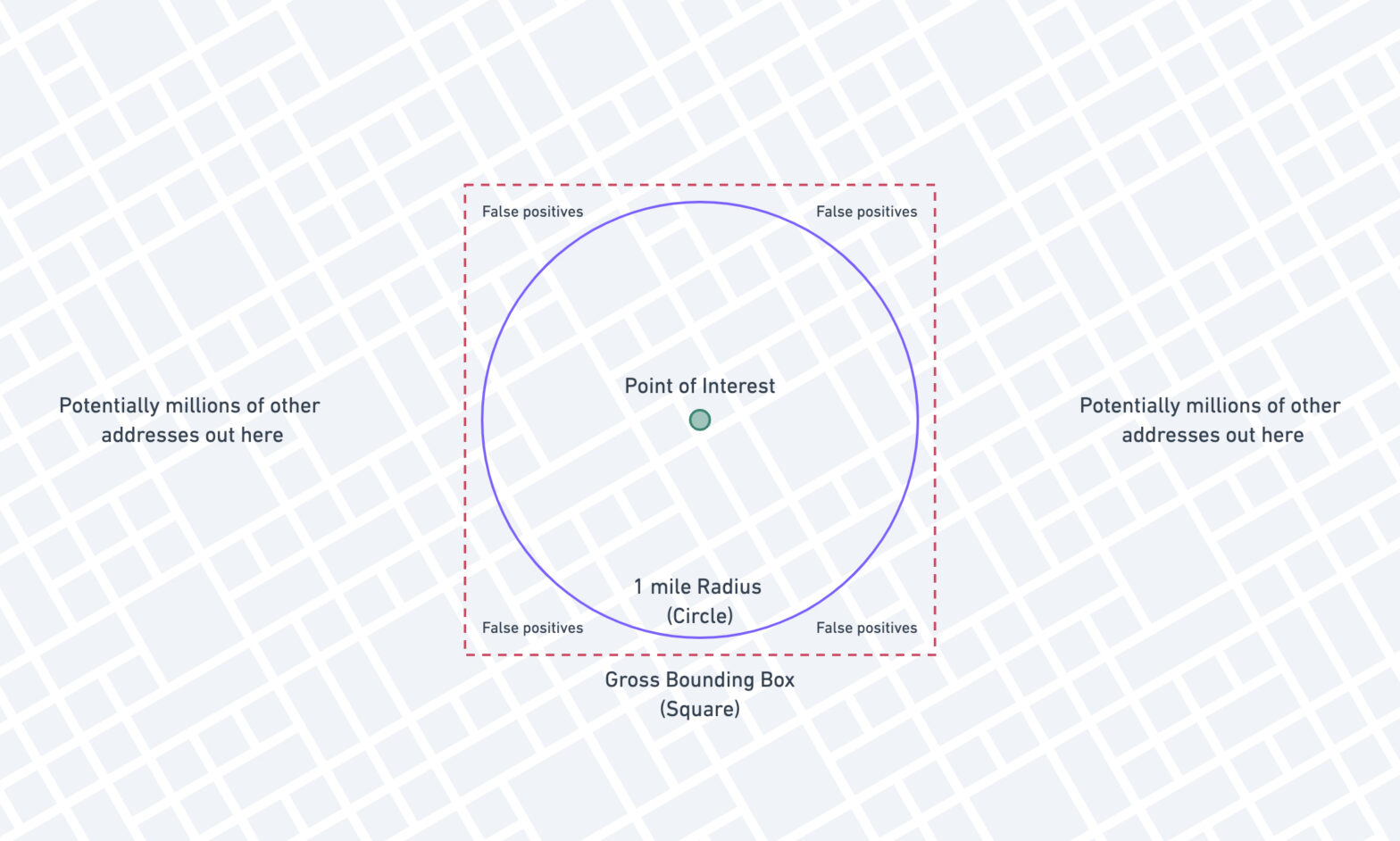
Efficient Distance Querying in MySQL
A rather geeky/technical weblog, est. 2001, by Bramus
ORDER BY RANDOM()

Jerod Santo: There are plenty of times in my career when I’ve stored a boolean and later wished I’d had a timestamp. There are zero times when I’ve stored a timestamp and regretted that decision. Hear hear! Over the years I’ve come to include 9 meta fields for most of the tables I create: added_at, …

Interesting post over at the Flare blog, where they had to delete over 900 million records from a MySQL table. They couldn’t simply run a DELETE FROM table query, as that would lock it: When a deletion query using a WHERE clause starts, it will lock that table. All other queries that are run against …
Continue reading “How to delete lots of rows from a MySQL database without indefinite locking”
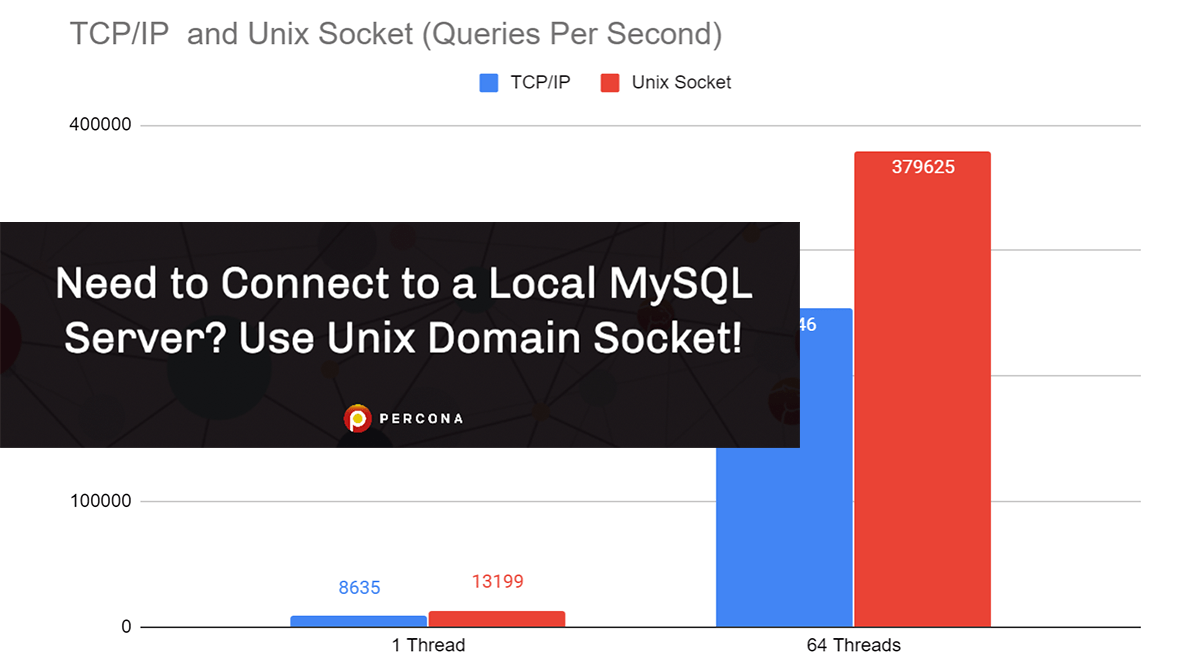
The folks at Percona have benchmarked TCP/IP vs. Unix Connections to a local MySQL server. When connecting to a local MySQL instance, you have two commonly used methods: use TCP/IP protocol to connect to local address – localhost or 127.0.0.1 – or use Unix Domain Socket. If you have a choice (if your application supports …
Continue reading “Need to Connect to a Local MySQL Server? Use Unix Domain Socket!”
"Terminated due to signal: ABORT TRAP (6)"
Photo by Clem Onojeghuo on Unsplash To connect to a MySQL Server that requires SSL from PHP with PDO, you can use this piece of code: try { $db = new PDO('mysql:host=DB_HOST;dbname=DB_NAME', $user, $pass, [ PDO::MYSQL_ATTR_SSL_KEY => 'path/to/client_private_key', PDO::MYSQL_ATTR_SSL_CERT => 'path/to/client_cert', PDO::MYSQL_ATTR_SSL_CA => 'path/to/server_ca_cert', ]); } catch (PDOException $e) { print "Error!: " . $e->getMessage() …
Recently the folks from Spatie released a security update for their laravel-query-builder package. Turns out it was vulnerable to SQL Injection. At the core of the vulnerability is the fact that Laravel offers a shorthand for querying only certain fields of JSON data, but that these do not get escaped when converted to a json_extract …
ST_Distance_Sphere PolyfillOne of the cool things about MySQL 5.7 is the fact that it sports a few spatial convenience functions (since 5.7.6), allowing one to do operations on geometric values. One of those convenience functions is ST_Distance_Sphere, which allows one to calculate the (spherical) distance between two points. Recently I was working an project where I …
At GitHub they use MySQL as their main datastore. The setup is a typical “single-writer-multiple-readers” design. They loadbalance between server pools using HAProxy, with some cleverness built in: Instead [of checking whether a MySQL server is live with mysql-check], we make our HAProxy pools context aware. We let the backend MySQL hosts make an informed …
Postgres served us well in the early days of Uber, but we ran into significant problems scaling Postgres with our growth. In this article, we’ll explore some of the drawbacks we found with Postgres and explain the decision to build Schemaless and other backend services on top of MySQL. Why Uber Engineering Switched from Postgres …
Continue reading “Why Uber Engineering Switched from Postgres to MySQL”