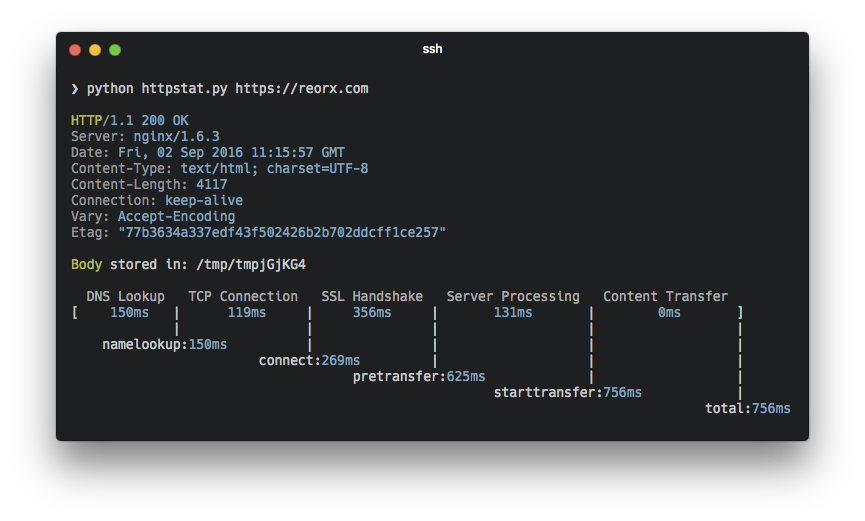
Over at Smashing Magazine, Robin Marx has written a 3-part series on HTTP/3: After almost five years in development, the new HTTP/3 protocol is nearing its final form. Earlier iterations were already available as an experimental feature, but you can expect the availability and use of HTTP/3 proper to ramp up over in 2021. So …