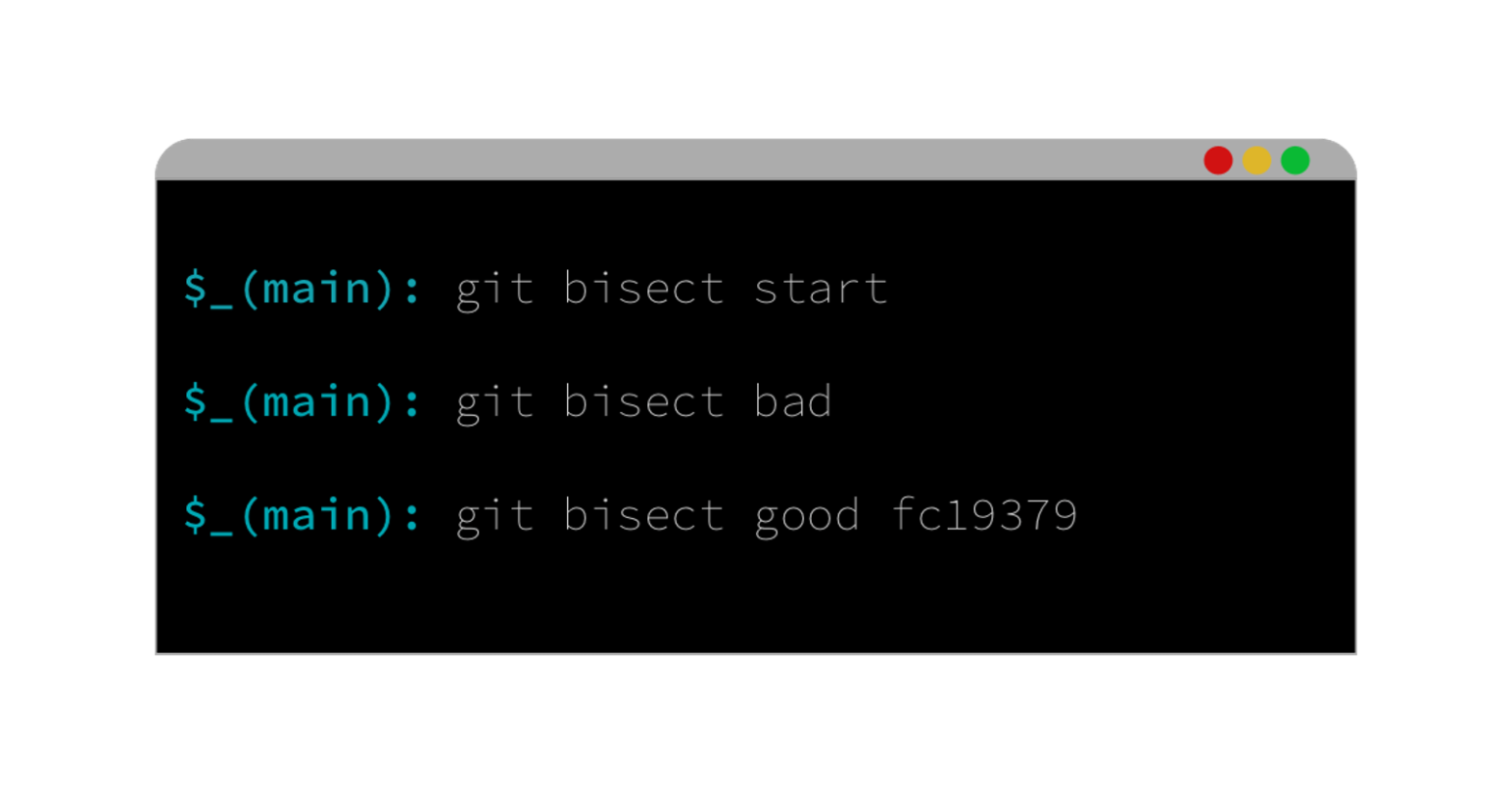
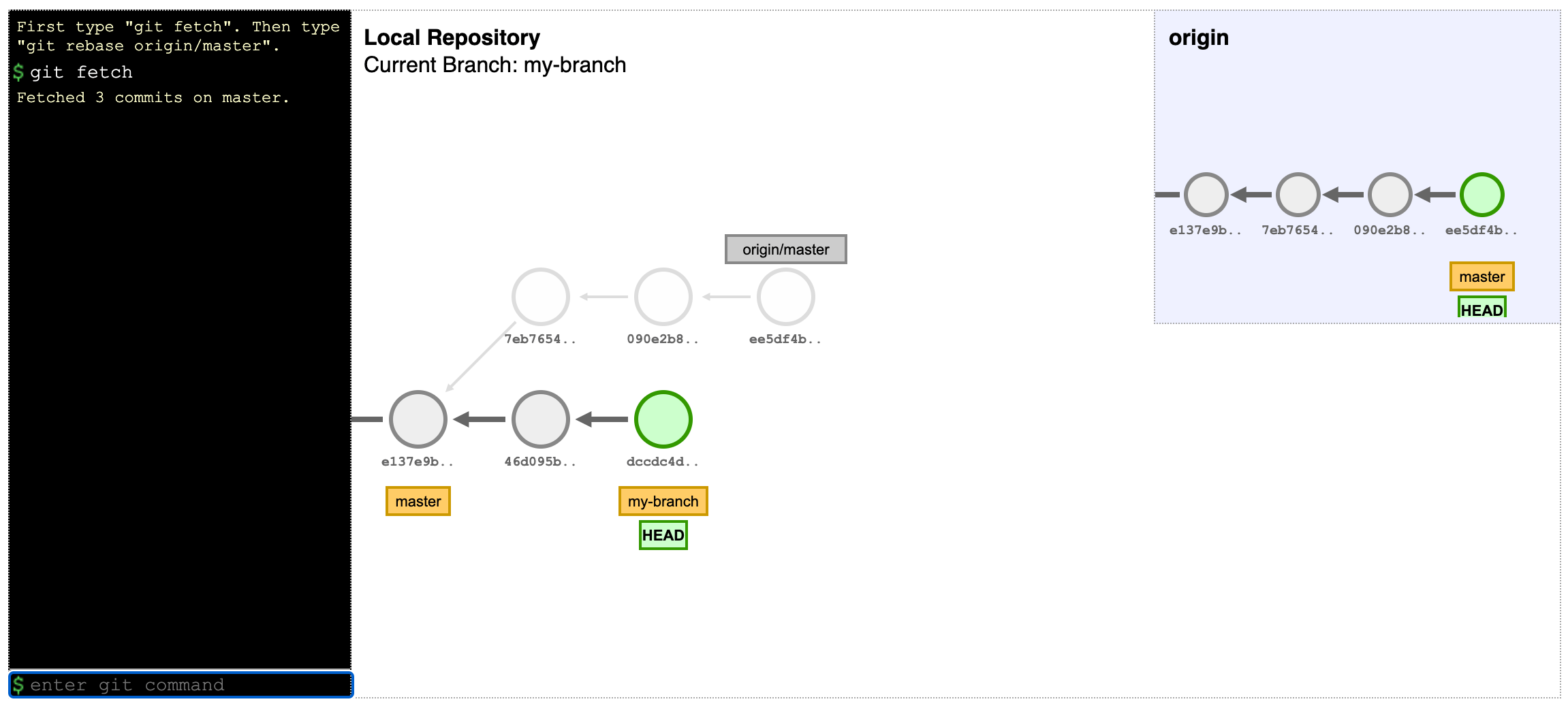
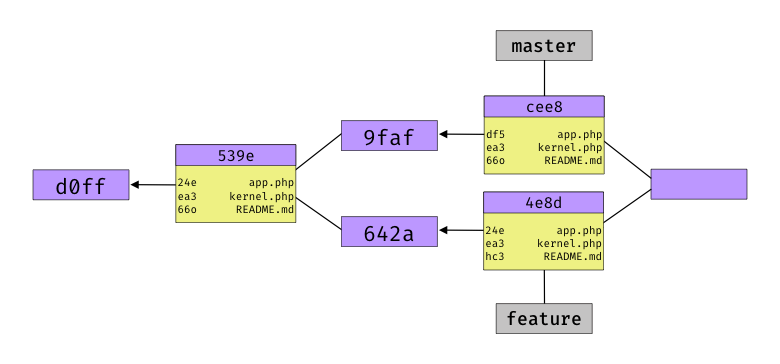
If you’re using Dropbox and would like to store Git repos in your Dropbox folder, this tool is useful: This CLI shell script aims to take advantage of glob patterns and existing .gitignore files in order to exclude specific folders and files from dropbox sync. Never sync node_modules or vendor to Dropbox again! dropboxignore →